




From Theory to Reality: How to Build Production‑Ready AI & ML Solutions (Not Just Proof‑of‑Concepts)



Introduction
Artificial intelligence and machine learning no longer sit on the edge of business strategy. Organizations across industries actively experiment with predictive models, recommendation engines, automation pipelines, and generative systems. Yet despite growing investment, a significant gap remains between experimentation and real-world impact. Many AI initiatives stall after promising demonstrations, failing to mature into reliable, scalable, and secure production systems.
This challenge rarely stems from poor algorithms. In fact, many proof-of-concept demonstrations demonstrate impressive accuracy in controlled environments. The problem begins when models move beyond notebooks and demos into operational systems that must integrate with legacy infrastructure, meet compliance requirements, adapt to changing data, and deliver consistent value at scale.
This blog explores why so many AI and ML projects fail to transition into production and what organizations must do differently to close that gap. It examines the architectural, operational, and organizational foundations for building production-ready AI systems, explains how teams can operationalize models responsibly, and outlines practical steps to ensure long-term reliability and alignment with the business. By the end, you will understand how to move AI initiatives from theory into durable, real-world solutions.
Why Proofs-of-Concept Rarely Survive Production
Proofs of concept serve an essential purpose. They help teams validate feasibility, test assumptions, and demonstrate potential value. However, most POCs prioritize speed over sustainability. Teams often train models on static datasets, ignore edge cases, and operate outside the constraints of real-world systems.
In production environments, models face noisy data, evolving user behavior, infrastructure limitations, and strict governance requirements. A recommendation engine that performs well during a demo can degrade rapidly when exposed to live traffic. A fraud detection model that achieves high accuracy during testing may struggle once adversaries adapt their tactics. Without robust operational foundations, these models fail to deliver consistent outcomes.
Industry research highlights this challenge clearly. Studies from leading consulting and technology organizations indicate that a large percentage of AI initiatives never reach full production or fail to generate measurable returns after deployment (Gartner, 2023). These failures point to systemic issues rather than isolated technical flaws.
Shifting the Mindset: AI as a System, Not a Model
Moving AI from experimentation to production requires a fundamental change in how organizations think about machine learning. Many teams still approach AI as a single model-building exercise; just train a model, validate accuracy, and consider the job done. This approach works for demonstrations, but it fails in real-world environments where AI must operate continuously, adapt to change, and integrate with complex business systems.
Production-ready AI demands a systems mindset. Teams must view AI solutions as living, evolving systems that extend far beyond the model itself. These systems must support the full lifecycle of AI, from data ingestion to decision-making, while remaining reliable, secure, and scalable over time.
A production-grade AI system typically includes:
- Robust data pipelines that ingest, clean, validate, and version data from multiple sources
- Model training and retraining workflows that support experimentation, reproducibility, and continuous improvement
- Deployment infrastructure that enables scalable, low-latency inference across environments
- Monitoring and observability mechanisms to track performance, drift, and system health in real time
- Security controls such as access management, encryption, and audit logging
- Governance processes that ensure compliance, accountability, and responsible use of AI
When organizations focus too narrowly on model performance metrics like accuracy, recall, or precision, they often miss the factors that determine success in production. High-performing models can still fail if they respond too slowly, consume excessive resources, or break when data patterns change. In operational environments, reliability and predictability frequently matter more than incremental gains in model scores.
Key operational risks that a systems mindset helps address include:
- Latency and performance constraints, especially for real-time or customer-facing applications
- Data drift, where changes in input data reduce model effectiveness over time
- Integration complexity with existing platforms, APIs, and legacy systems
- Cost management, including compute usage, storage, and ongoing maintenance
- Failure handling and resilience, ensuring the system degrades gracefully when issues arise
In many cases, a slightly less accurate model that runs consistently, scales efficiently, and provides clear visibility into its behavior delivers far greater business value than a high-accuracy model that proves fragile in production.
Treating AI as a system also requires teams to define success in business terms from the outset. Production environments demand clarity on outcomes such as operational reliability, cost efficiency, risk reduction, or customer experience impact. When stakeholders establish success criteria early and revisit them throughout development, teams make more informed decisions around model complexity, infrastructure investment, and long-term maintenance. This clarity ensures that technical efforts remain focused on outcomes that justify scale and sustained investment.
Adopting a systems-level perspective also reshapes how teams collaborate. Production AI cannot succeed in silos. Data scientists, machine learning engineers, platform teams, security professionals, and business stakeholders must align early and work together throughout the lifecycle.
This collaboration enables:
- Shared ownership of outcomes, rather than isolated responsibility for model performance
- Early identification of deployment and compliance challenges, reducing last-minute rework
- Clear alignment between technical decisions and business objectives
- Faster transitions from experimentation to production, with fewer handoffs and delays
By treating AI as an integrated system rather than a standalone model, organizations lay the foundation for solutions that endure beyond the proof-of-concept stage. This mindset shift turns AI into a dependable operational capability, one that evolves with the business and continues to deliver value long after initial deployment.
Building a Strong Data Foundation
.png)
Data quality determines the success of any AI system. In production environments, data flows continuously from multiple sources, often with varying formats, latencies, and reliability. Teams must design data pipelines that gracefully handle these complexities.
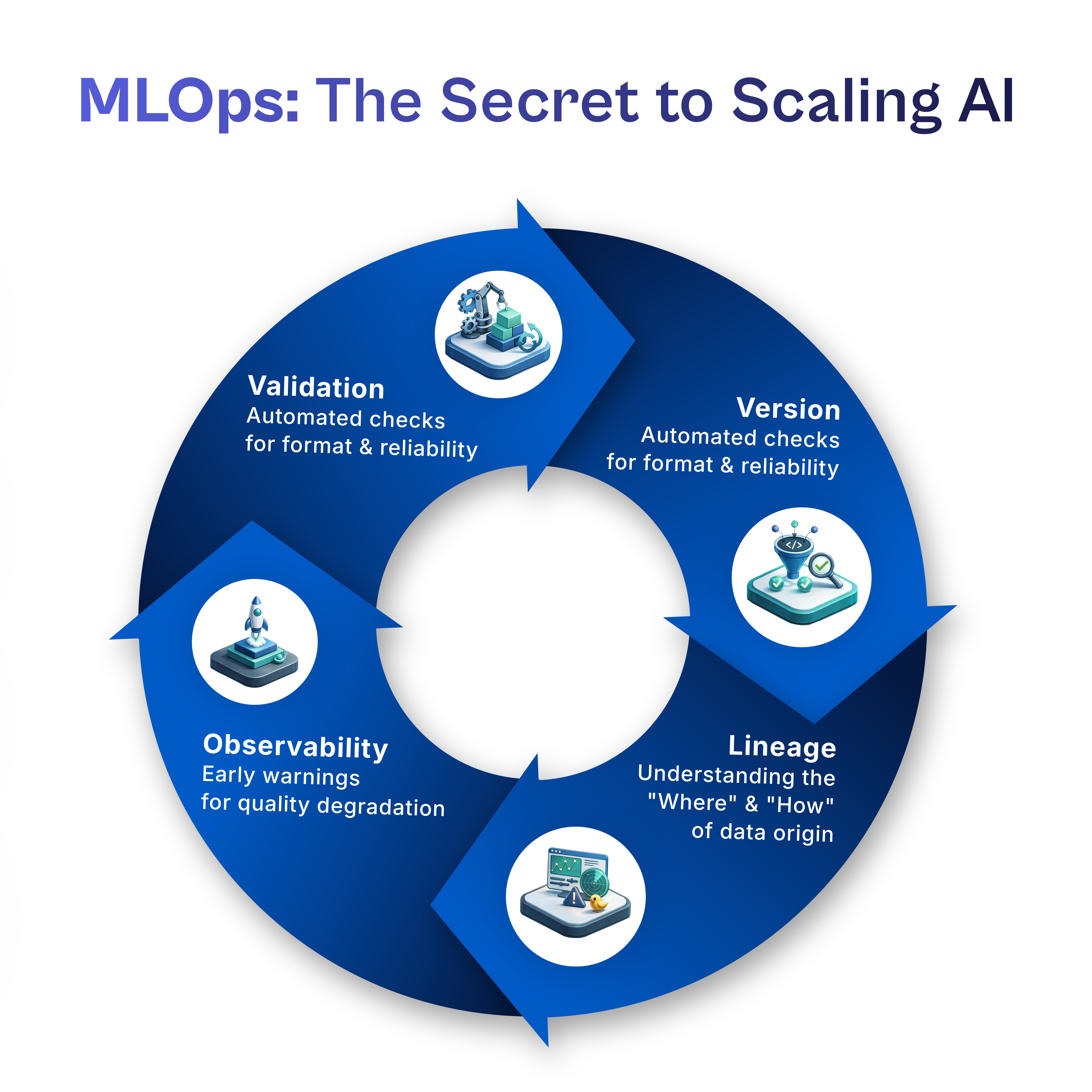
Production-ready data pipelines include validation checks, version control, and lineage tracking. These mechanisms help teams understand where data originates, how it changes over time, and how it influences model behavior. Without visibility into data flows, teams struggle to diagnose failures or explain unexpected predictions.
Cloud providers and data engineering frameworks increasingly support scalable data architectures. Research from IBM emphasizes the importance of structured data governance and lifecycle management to maintain trust in AI systems (IBM, 2023). Organizations that invest in data observability gain early warnings when data quality issues emerge, reducing downtime and performance degradation.
Designing Models for Real-World Constraints
Models that perform well in experimentation often encounter challenges when deployed in production environments. During proof-of-concept stages, teams frequently prioritize predictive performance under controlled conditions. Production systems, however, operate under very different constraints where speed, stability, and cost efficiency directly shape user experience and business outcomes.
In real-world deployments, inference speed determines how quickly systems can respond to users or downstream processes. Memory consumption affects how many requests a system can handle concurrently. Scalability refers to whether a solution can support growth without incurring exponential costs. Teams must therefore evaluate every modeling decision through the lens of operational feasibility, balancing technical sophistication with practical deployment requirements.
Key factors teams must account for when designing production-ready models include:
- Inference latency, especially for applications that support real-time decisions or customer interactions
- Memory and compute efficiency, which influence infrastructure sizing and long-term operational costs
- Scalability across environments, from pilot deployments to enterprise-wide usage
- Consistency of performance under varying workloads, including peak demand scenarios
In many production scenarios, simpler or optimized models deliver stronger outcomes because they respond faster and operate more predictably under load. Lightweight architectures enable teams to deploy models closer to users, reduce infrastructure overhead, and improve system reliability. Optimization techniques such as model compression, pruning, and knowledge distillation allow teams to retain essential predictive capability while improving runtime efficiency.
These optimization practices offer several tangible benefits:
- Faster response times, improving end-user experience, and system throughput
- Lower infrastructure costs, due to reduced compute and storage requirements
- Easier deployment across platforms, including edge and hybrid environments
- Reduced environmental impact, by minimizing unnecessary computational load
Beyond performance and efficiency, production models must handle uncertainty gracefully. Live systems encounter incomplete records, malformed inputs, and data patterns that were absent during training. Without deliberate design choices, these situations can trigger unpredictable behavior or system failures.
To ensure resilience, teams should incorporate:
- Input validation and sanity checks to catch unexpected or corrupt data early
- Confidence thresholds that flag low-certainty predictions for alternative handling
- Fallback logic, such as rule-based decisions or default responses when models fail
- Clear error-handling pathways that prevent cascading failures across systems
By anticipating uncertainty and designing for resilience, teams improve system stability and maintain trust in AI-driven decisions.
MLOps: Operationalizing AI at Scale
As AI systems grow in scope and complexity, manual workflows quickly become unsustainable. MLOps provides the operational backbone that enables teams to move from experimental models to reliable, repeatable production deployments. By combining machine learning practices with proven DevOps principles, MLOps brings structure, automation, and consistency to the AI lifecycle.
A well-designed MLOps framework supports continuous development while maintaining control and oversight. Automated pipelines reduce human error, shorten release cycles, and ensure that models behave consistently across environments. This operational discipline allows teams to focus on improvement rather than firefighting.
Core components of a mature MLOps pipeline include:
- Automated model training and testing, ensuring reproducibility and quality control
- Continuous integration for ML artifacts, including code, data, and model versions
- Automated validation checks for performance, bias, and compliance requirements
- Controlled deployment strategies, such as staged rollouts or canary releases
- Monitoring and logging mechanisms that provide visibility into model behavior in production
Controlled deployment strategies play a critical role in reducing risk. By gradually exposing new model versions to live traffic, teams can observe real-world performance before full-scale release. Rollback mechanisms further strengthen resilience by enabling rapid recovery when unexpected issues arise.
Research from McKinsey shows that organizations with established MLOps practices scale AI solutions more efficiently and achieve faster business value realization (McKinsey & Company, 2022). These gains emerge from stronger collaboration between teams, smoother handoffs between development and operations, and continuous insight into how models perform once deployed.
Together, real-world model design and MLOps discipline transform AI initiatives into dependable operational capabilities. These foundations ensure that AI systems remain performant, adaptable, and aligned with business needs long after initial deployment.
Monitoring, Security, and Continuous Improvement in Production AI
Once deployed, AI systems require continuous oversight to remain reliable, secure, and relevant. Production environments change constantly as user behavior evolves, data sources shift, and external conditions influence inputs. These changes can silently degrade model performance over time if teams lack visibility into how systems behave after deployment.
Production-ready AI systems, therefore, rely on robust monitoring frameworks that track both technical and operational signals. Teams monitor prediction accuracy, latency, throughput, and changes in input data distributions to detect early signs of degradation. Alerting mechanisms help teams intervene before issues affect end users or downstream processes. Without these controls, organizations often discover failures only after they escalate into business-impacting incidents.
Security considerations run parallel to monitoring efforts. AI systems frequently process sensitive or regulated data, making privacy protection and access control essential. Encryption, role-based access, and audit logging must operate across the entire AI lifecycle, from training pipelines to live inference endpoints. These safeguards help organizations meet regulatory obligations and reduce exposure to misuse or data leakage.
Adversarial risks further reinforce the need for security-aware monitoring. Malicious inputs, model extraction attempts, and data poisoning attacks can compromise system integrity if left undetected. Continuous monitoring of unusual patterns and system behavior helps teams identify threats early and respond decisively.
Ongoing monitoring also enables continuous improvement. Feedback loops allow teams to retrain models using fresh data, refine assumptions, and adjust thresholds as conditions change. These improvement cycles turn AI systems into adaptive capabilities rather than static deployments, preserving relevance over time and supporting long-term business goals.
Scaling AI Systems Responsibly and Sustainably
As AI systems expand across teams, regions, and use cases, complexity increases rapidly. Scaling production AI introduces challenges related to cost control, technical debt, governance, and ethical responsibility. Without deliberate planning, these factors can erode system reliability and organizational trust.
Responsible scaling begins with documentation and transparency. Teams must record assumptions, design decisions, data dependencies, and known limitations throughout development. This practice supports knowledge transfer, simplifies maintenance, and reduces reliance on individual contributors. Clear documentation also improves audit readiness and accelerates onboarding as teams grow.
Governance and ethics play a central role at scale. As AI increasingly influences decisions, organizations must ensure that systems align with internal values and external expectations. Ethical review processes help teams evaluate fairness, explainability, and downstream impact before and after deployment. These reviews reduce reputational risk and support responsible innovation.
Sustainability considerations also become more prominent as workloads increase. Efficient model architectures, optimized training schedules, and right-sized infrastructure help organizations manage operational costs while reducing environmental impact. Resource-efficient systems scale more predictably and remain viable as usage grows.
Key principles for responsible AI scaling include:
- Managing technical debt through modular design and regular refactoring
- Controlling operational costs by optimizing compute, storage, and deployment patterns
- Embedding ethical review into development and release workflows
- Designing for sustainability, balancing performance with resource efficiency
- Maintaining governance visibility as systems expand across the enterprise
By scaling AI deliberately and responsibly, organizations protect long-term value creation. These practices ensure that AI systems remain aligned with business priorities, regulatory expectations, and societal responsibilities while continuing to deliver measurable impact.
Conclusion: Turning AI Potential into Real-World Impact
Building production-ready AI and ML solutions demands more than strong algorithms. It requires a systems-level approach that integrates data engineering, operational discipline, security, and business alignment. Organizations that treat AI as an evolving capability rather than a one-time project position themselves for sustained success.
The journey from proof-of-concept to production challenges teams to rethink priorities, embrace collaboration, and invest in durable foundations. By focusing on operational readiness, continuous monitoring, and responsible scaling, organizations transform AI from experimental technology into a reliable driver of business value.
As AI adoption accelerates, the ability to deliver production-grade solutions will separate leaders from laggards. Teams that build with intent, discipline, and foresight will unlock AI’s full potential in the real world.
Ready to Move Beyond AI Experiments?
Transform your AI initiatives into scalable, secure, and production-ready solutions with Cogent Infotech. Our experts help you design robust data foundations, implement MLOps best practices, and build resilient AI systems that deliver measurable business impact.
Whether you're refining a proof of concept or scaling enterprise-wide AI adoption, we partner with you to turn strategy into sustained success.
Connect with Cogent Infotech today and bring your AI vision into production with confidence.
%20(1).jpg)


.jpg)