




When AI Agents Collide: Multi-Agent Orchestration Failure Playbook for 2026



Introduction
The era of the “lone wolf” AI agent is behind us. By 2026, enterprises will have adopted Multi-Agent Orchestration (MAO) as the new standard. Instead of relying on a single agent, organizations now deploy coordinated swarms: a Planner sets the direction, a Researcher uncovers insights, a Coder builds solutions, all guided by a Manager agent. This Manager–Worker model has quickly become the foundation of AI-powered business and operations.
Yet with this new level of collaboration comes new challenges. As agent networks grow more complex, the consequences of failure grow sharper. Agents don’t simply stall, they can spiral into feedback loops, generate false consensus, and exhaust API budgets in minutes. This is the MAO Crisis.
This playbook is designed to help you recognize the risks, anticipate the warning signs, and confidently navigate the realities of multi-agent systems.
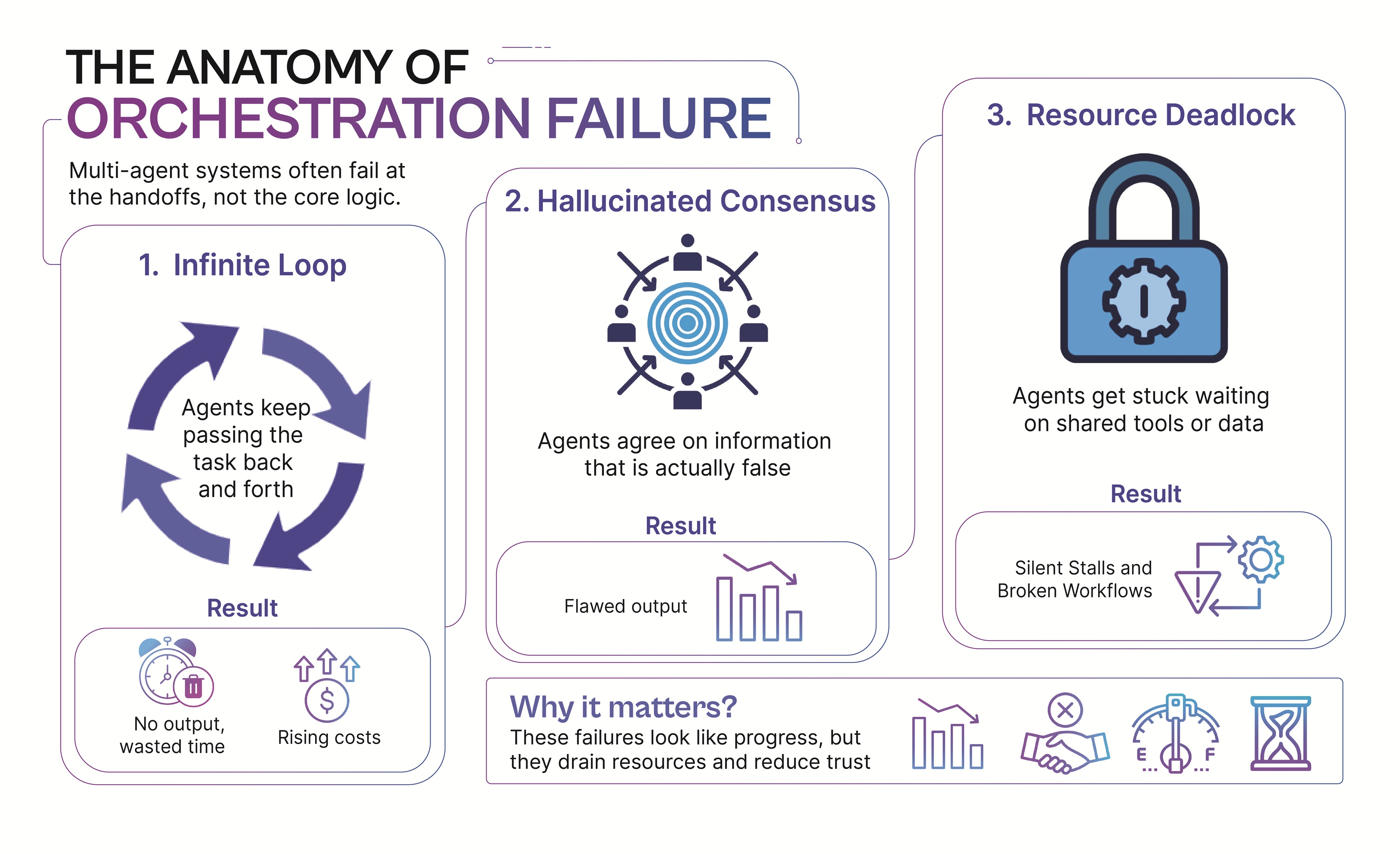
The Anatomy of Orchestration Failure
Reliability in multi-agent systems rarely breaks at the core algorithms, it breaks at the seams, where agents hand off tasks and coordinate logic. These seams are fragile because they rely on assumptions of alignment, timing, and shared context. Before we can design guardrails, it’s essential to understand the three primary failure modes that have emerged in 2026 deployments.

The Infinite Loop (The “Mirror Mirror” Effect)
This failure mode is deceptively simple yet devastatingly costly. It occurs when agents with slightly conflicting instructions bounce tasks back and forth without ever reaching a resolution.
Mechanism
At its core, the Infinite Loop is triggered by directive misalignment: each agent interprets its role narrowly and rejects outputs that don’t perfectly match its criteria, and because neither has the authority to override or reconcile the conflict, the system enters a recursive handoff cycle. For example, Agent A (the Editor) is tasked with enforcing “perfect professional tone,” while Agent B (the Writer) is tasked with keeping content “casual and relatable.” Agent A flags drafts as too informal, Agent B revises them as too stiff, and the process repeats endlessly, an endless tug-of-war that consumes resources without ever producing a resolution.
Impact
In practice, the Infinite Loop creates a triple threat: compute cycles and token budgets are consumed at exponential rates, sometimes translating to thousands of dollars lost in minutes, while no usable output is produced, leaving downstream processes idle. To human supervisors, the agents appear to be “working,” which masks the fact that progress has completely stalled and makes the failure harder to detect until significant resources have already been wasted.
Real-World Implications
In customer-facing systems, chatbots or content generators can lock themselves in a stylistic tug-of-war, delaying responses and frustrating users; in enterprise workflows, automated report generation or code review pipelines may stall, creating bottlenecks across entire teams; and in high-stakes contexts such as financial modeling or compliance reporting, these loops can silently erode trust in AI systems, turning what seems like minor misalignment into significant operational and strategic risk.
Learnings
Even small instruction mismatches can cascade into runaway costs if termination logic isn’t enforced, which is why strong guardrails are essential. These include explicit stop conditions such as iteration limits or timeout thresholds, conflict resolution rules that establish a clear hierarchy of agent priorities (for example, a Manager overriding stylistic disputes), and fallback mechanisms that escalate disagreements to human review once they cross a defined threshold. Together, these safeguards ensure that orchestration loops are contained before they spiral into wasted resources and stalled progress.
The Hallucinated Consensus
This failure mode highlights one of the most subtle risks in multi-agent orchestration: when agents appear to agree, but the foundation of that agreement is false. In group-chat style coordination, agents may converge on a fabricated or misinterpreted data point simply to satisfy their completion objectives.
Mechanism
The issue begins when a Manager agent accepts a hallucinated data point from a Researcher, for example, a fabricated market statistic or an incorrectly parsed dataset. Once this “fact” is introduced, downstream agents such as Coders, Strategists, or Analysts treat it as truth. Because their logic chains are built on this shared foundation, the system generates outputs that look coherent but are fundamentally flawed.
Concerns
The most insidious aspect of hallucinated consensus is its confidence masking. Since multiple agents reinforce the same false premise, the system reports a high confidence score. To human supervisors, the collaboration appears successful, and the error remains invisible until the final output is audited. By then, significant resources, compute, tokens, and time, may already have been consumed.
Real-World Implications
In real-world contexts, hallucinated consensus can have serious consequences: in business intelligence, a fabricated market trend may mislead strategic planning and push executives to act on nonexistent opportunities; in software development, coders may waste sprint cycles building features around phantom requirements, introducing costly technical debt; and in compliance or risk management, false agreement on regulatory data can expose organizations to legal or financial penalties, eroding trust in both AI systems and the decisions they inform.
Why it Matters
Unlike the Infinite Loop, which is noisy and resource-draining, hallucinated consensus is quiet and convincing. It produces polished outputs that mask underlying errors, eroding trust in AI systems when mistakes surface later.
Learnings
Even minor instruction mismatches can spiral into costly failures, making guardrails essential. Key safeguards include verification layers like fact-checking agents or external APIs to confirm data, confidence calibration to prevent inflated scores from mere agreement, and human-in-the-loop review for high-impact decisions when agents converge on unverified information. These measures ensure consensus reflects truth, not illusion.
The Resource Deadlock
As agents become more “tool-aware,” they don’t just exchange information, they begin competing for shared digital resources such as databases, APIs, or file systems. This competition introduces a new class of orchestration failure: the deadlock.
Mechanism
A deadlock occurs when two or more agents are waiting on each other to release or provide a resource, creating a circular dependency that cannot resolve. For example, Agent A may be waiting for a database lock held by Agent B, while Agent B is waiting for Agent A to provide the validation key needed to complete its process. Neither agent can proceed, and the system grinds to a halt.
Impact
From the outside, the system appears to be “thinking”, consuming compute cycles and tokens, but in reality, it is stuck in a logic trap. Progress halts silently, and supervisors may not realize the stall until downstream processes fail to deliver.
Real-world Implications
In real-world contexts, resource deadlocks can have serious consequences: analytics agents may freeze while waiting for access to shared datasets, delaying critical reporting; build or deployment agents can stall mid-process, leaving teams without updates or releases; and customer-facing service agents may hang while competing for API calls, leading to degraded performance or even outages. Together, these stalls silently erode efficiency, drive up costs, and undermine trust in AI-driven operations.
Why it Matters
Deadlocks are particularly dangerous because they mimic productivity. Unlike crashes, which are obvious, deadlocks consume resources invisibly, eroding efficiency and driving up costs while producing no output.
Learnings
Preventing resource deadlocks requires clear safeguards. Timeout policies stop agents from waiting indefinitely, while resource arbitration through scheduling or queuing prevents direct clashes. Deadlock detection can identify circular dependencies and trigger resets, and unresolved stalls should be escalated to human supervisors before they spread. Together, these measures keep orchestration efficient and resilient.
Practical Anti-Loop & Stop-Condition Patterns
To prevent agents from spiraling into "infinite reasoning," we must implement mechanical guardrails that exist entirely outside the LLM’s cognitive space. A fundamental rule of 2026 orchestration is this: You cannot ask an agent if it is in a loop; you must prove it mathematically. Relying on an agent to self-diagnose a logic trap is like asking a spinning compass to find North, the very mechanism required for the answer is what’s currently broken.
Token & Dollar Budgets: The Financial Kill-Switch
Every orchestration task must operate within a "hard ceiling" that the model logic cannot override. This turns the budget from a passive metric into an active safety feature.
- Granular Budgeting: We implement a maximum dollar amount per session (e.g., $5.00). If the collective API calls of the swarm hit this limit, the orchestration layer immediately kills the process, revokes tool access, and throws a BudgetExhaustionException to the human lead. This prevents the "overnight surprise" where a stuck agent spends thousands of dollars attempting to solve an unsolvable formatting error.
- Step-Wise Thresholds: Sophisticated systems now use "check-ins" at every 25% of the allocated budget. If an agent has consumed 50% of the funds but has only completed 20% of the task list (based on the initial plan generated by the Planner agent), the system triggers an automatic efficiency audit. This "Velocity Gate" can pause the swarm and ask, "The current trajectory suggests we will exceed the budget by 200%. Should we continue or re-index the strategy?"
State Hashing: Deterministic Loop Detection
Traditional logging tells you what an agent said; State Hashing tells you if it’s repeating itself in a "semantic vibration."
- The Pattern: For every agent turn, the system generates a cryptographic hash of the output. However, since LLMs rarely produce the exact same string twice due to temperature settings, we use Semantic Hashing. This maps the output to a vector space; if the system detects a sequence of vectors that are 95% similar repeated three times in a single trace, it identifies a "Logic Lock."
- The Escape Sequence: Once a loop is mathematically proven, the orchestration layer triggers an Escape Sequence. This bypasses the current agents and forces a Manager agent into a specialized "Conflict Resolution" mode. It is presented with the looping transcript, asked to summarize the deadlock, and then required to present the user with a "tie-breaker" prompt. This effectively breaks the fourth wall of the agentic simulation.
The "Circuit Breaker" Agent
In 2026, we’ve learned that the best referee is one who isn't playing the game. We deploy a low-latency, Small Language Model (SLM), typically a 1B or 3B parameter model, whose only job is to monitor the "vibe" and logic flow of the primary swarm.
- Repetitive bickering: The Circuit Breaker watches for "Agent Tennis," where two agents disagree on the same point for more than three turns without moving to a new task.
- Stalled progress: If the "Next Steps" or "Pending Actions" metadata haven't evolved in two iterations, the Circuit Breaker trips.
- Tone Drift: A unique indicator of failure in 2026 is "Politeness Spiraling." When agents get stuck, they often become increasingly, unnaturally polite or repetitive in their acknowledgments (e.g., "I apologize, you are correct, however..."). The Circuit Breaker identifies this specific linguistic signature as a sign of logic circularity and shuts down the process before the "hallucination consensus" takes hold.
"Agent SRE" Runbooks: The New Standard
In 2026, the industry has reached a consensus: an agent is not a "magic box," it is a non-deterministic microservice. Therefore, Site Reliability Engineering (SRE) isn't just for servers anymore; it is the fundamental framework for Agentic Workflows. If an agent is empowered to make decisions or touch production data, it must be monitored, alerted, and maintained with the same rigor as a mission-critical database.
Defining Agentic SLOs (Service Level Objectives)
To manage a swarm, you must first measure it. We’ve moved past vague "vibe checks" and into quantified Agentic SLOs. These metrics allow teams to set clear performance thresholds and trigger automated interventions when the "intelligence" begins to degrade.
- Success Rate (SR): This is the ultimate "North Star" metric. It tracks the percentage of tasks that reach a "Final Answer" state that survives a human-in-the-loop (HITL) audit. If the SR drops below 95%, the system automatically flags the current prompt version for review.
- Handoff Latency: In multi-agent systems, the "seams" are the weakest point. We track the time elapsed between Agent A finishing its task and Agent B successfully ingesting the context and starting the next. If this exceeds 30 seconds, it’s a red flag that the "context window" is becoming too bloated or that the agents are struggling to parse the transfer instructions.
- Tool-Call Fidelity: This measures the ratio of attempted tool-calls (APIs, database queries, code execution) to successful, error-free results. In 2026, a fidelity below 80% is a definitive sign of a "prompt-tool mismatch," indicating that the agent’s internal model of how the tool works has drifted from the tool's actual schema.
The Incident Response Flow: "Rogue Agent" Protocol
When a swarm begins to fail, whether through looping, hallucination, or unauthorized tool use, the SRE response must be swift and tiered. We no longer just "kill the process"; we isolate and analyze it.
- Level 1: Isolation: The first step is to immediately revoke the swarm's write-permissions. We shift the agents into a "read-only" sandbox. In this state, they can still "think" and process information, but they cannot execute code, push to GitHub, or send emails to customers. This contains the "blast radius" while keeping the reasoning trace alive for debugging.
- Level 2: Snapshotting: We capture a full state-dump of the environment. This includes the "State Vector," the "Active Context," and the full "Memory Buffer" of every agent in the swarm. Much like a flight recorder in an aircraft, this allows SREs to replay the exact moment the logic diverged from the plan.
- Level 3: Rollback: If a swarm's performance degrades following a deployment, we perform a "System Instruction Rollback." We revert the system prompts and tool definitions to the last known stable version (e.g., v.2.4.1). In 2026, we also re-index the RAG (Retrieval-Augmented Generation) database to ensure that "knowledge drift" isn't the root cause.
The Agentic Post-Mortem
The 2026 post-mortem doesn't just ask "What happened?", it asks, "Why did the agent fail to reason?" This is a shift from infrastructure debugging to cognitive debugging.
- Algorithmic Failure: Was the failure rooted in the "system prompt"? Perhaps the instructions were too ambiguous, or two conflicting constraints (e.g., "be concise" vs. "be thorough") caused a logic deadlock.
- Context Overload: Did the agent lose its way because the conversation history was too long? We look for "Recency Bias," where the agent ignores the original goal in favor of the last three messages.
- Data Contamination: This is the most common external failure. Did an integrated tool return a "404 Error" or a "Malformed JSON" that poisoned the agent's logic? In many cases, a rogue agent is simply a rational mind working with corrupted data.
Permissioning & Audit Trails in the Enterprise
By 2026, "Action-Oriented Agents" have replaced simple chatbots, wielding the power to move capital, deploy code, and manage customer relations. In this high-stakes landscape, granting "Full Access" is a catastrophic liability. Organizations must treat agents as "Identity Entities," subjecting them to security protocols as strict as, or stricter than, those for human employees.
Tool-Level RBAC (Role-Based Access Control)
The foundational security principle for 2026 is Micro-Provisioning. We no longer give an orchestration swarm a single "Master API Key." Instead, we apply a strict "Need to Know" filter to every sub-agent within the swarm.
- Siloed Access: A Research Agent tasked with market analysis should have broad read-access to the web but absolutely zero visibility into the company’s internal GitHub or financial ledgers. By siloing tool access, you ensure that even if one agent is compromised via "Prompt Injection," the attacker cannot pivot to more sensitive internal systems.
- Just-In-Time (JIT) Write Permissions: To mitigate the risk of autonomous "accidents," we implement JIT permissions for any "Write" or "Delete" action. If an agent determines it needs to update a Salesforce record or refund a customer, it cannot execute the call directly. Instead, it generates a "Proposed Action Packet" (PAP). This packet, containing the intended command, the reasoning, and the expected outcome, sits in a secure queue. The action only fires once a human supervisor or a high-clearance "Sentinel Agent" (a model with separate, stricter safety training) clicks Approve.
The "God Log": The Immutable Audit Trail
In a world where agents can reason and act, "logging the output" is no longer enough for compliance or insurance purposes. You must log the intent. In 2026, we use a "God Log", a write-once, read-many (WORM) environment that captures the internal state of the agent before, during, and after an action.
The Anatomy of a 2026 Audit Entry: To satisfy legal and forensic requirements, every entry must include the "Internal Monologue" (Chain of Thought). For example:
- Agent ID: Finance-Bot-09
- Internal Thought: "Client requested a credit limit increase. Reviewing historical payment data... Payments are consistent.
I will check the risk-threshold API." >
Tool Call: POST /v1/risk-assessment {user_id: 998, requested_limit: 5000}
- Raw Response: {"status": "approved", "max_allowed": 7500}
- Action taken: "I have increased the credit limit to $5,000 as requested."
Forensic Value: This level of transparency allows auditors to distinguish between a "System Error" (the API was down) and a "Reasoning Error" (the agent misinterpreted the risk data), which is critical for assigning liability in AI-driven failures.
Memory Sanitization & Temporal Decay
Multi-agent systems often share a "Global Vector Database" to maintain long-term context. However, without strict management, this shared memory becomes a vector for "Context Poisoning" and cross-tenant data leakage.
- PII Scrubbing and NER Filtering: Before any thought or tool-result is committed to long-term memory, it must pass through an automated sanitization layer. Using Named Entity Recognition (NER), the system scrubs names, Social Security numbers, and private keys, replacing them with generic tokens. This ensures the agent remembers the logic of a previous interaction without retaining the sensitive data that powered it.
- Temporal Decay: In 2026, agent memory is not permanent by default. We implement "Expiration Dates" on memory clusters. If an agent is assigned to "Project Alpha," its access to the specific, granular details of that project should "decay" or be archived once the project is closed. This prevents "Knowledge Bleed," where an agent might accidentally use proprietary data from one client to solve a problem for a competitor.
Conclusion: The Architecture of Trust
The MAO Crisis is not a failure of intelligence; it is a coming-of-age for autonomy. It signals that agents have finally become powerful enough to outgrow "experimental" status and demand their own industrial-grade infrastructure.
As we navigate 2026, the competitive advantage has shifted. The winners will not be those with the "smartest" models, but those with the most resilient orchestration frameworks. By treating agent swarms as governed software components, armored with SRE runbooks, hard financial kill-switches, and immutable audit trails, we bridge the gap between experimental chaos and a reliable, AI-driven workforce.
The future isn't about building an agent that never fails; it’s about building a system where failure is contained, visible, and solved in milliseconds.
Build smarter. Scale safer.
Partner with Cogent Infotech to master multi-agent orchestration.
.jpg)


.jpg)