




Inference Economics: A CFO-Ready Guide to Preventing Runaway AI Spend



The Technology Report from Bain & Company projects that by 2030, there will be a $800 billion revenue gap from the development of AI infrastructure. Although strategically incorrect, this analysis is sound mathematically. AI systems will directly capture value from the $60 trillion global labor market, rather than from IT spending, resulting in the previously missing revenue. Businesses will pay for tasks and results rather than software licenses when agentic colleagues conduct cognitive work.
AI does not create value through licensing or subscriptions, in contrast to traditional software. It generates value through usage; inference costs are associated with each query, process, and automated operation. Because of this, investment in AI is very dynamic, frequently unpredictable, and closely related to business activity. In difficult situations, a lack of visibility and control has caused expenses to rapidly increase for organizations. That’s exactly why FinOps leaders are now treating AI as a separate cost-management discipline.
For CFOs, this introduces a new challenge. Managing AI spend isn’t just about reducing costs; it’s about understanding them. What does a single workflow cost? How does usage scale across departments? And how do those costs translate into measurable outcomes?
Stronger governance, more intelligent infrastructure choices, and a change toward unambiguous unit economics are necessary to address these issues. AI investments can quickly become challenging to manage without clear boundaries, real-time monitoring, and workload plans that are in line with privacy, latency, and utilization requirements.
Financial discipline will be crucial in differentiating between runaway spending and scalable innovation as businesses delve further into the inference economy.
Understanding Inference Economics: Essential Concepts for Smarter Business Decisions
Understanding inference economics is essential to managing expenses and optimizing value as businesses expand the usage of AI. AI expenses are directly related to usage, performance needs, and design choices, compared to traditional IT expenditures. Businesses must assess how models are implemented, optimized, and managed because each query, response, and automated process adds to continuing costs.
Leaders can make better decisions that balance cost, efficiency, and performance across AI-driven operations by dissecting the fundamental elements of inference economics.
- Inference vs Training: While it is typically a one-time expenditure, training a model requires a significant amount of capital. On the other hand, inference is the continuous expense of making forecasts, responding to enquiries, or producing information. It's comparable to the distinction between paying the electrical power bill and constructing a power plant.
- Latency & Throughput: Low-latency inference is frequently required for high-quality AI systems. This calls for the use of costly, efficient infrastructure. When you attempt to find a balance between speed, accuracy, and cost, tradeoffs quickly emerge.
- Model Dimensions & Effectiveness: Although larger models are frequently more accurate, their operating expenses are also much higher. Smaller models, while more affordable, may not always match the same level of performance. Teams are increasingly employing strategies like model routing, quantization, and distillation to achieve the ideal balance between cost and efficiency without significantly sacrificing quality.
Inference is no longer a technical afterthought, as all of this makes evident. It is an economic system-wide function.
Core Terminology for Understanding AI Inference Economics
Comprehending the principles of inference economics lays the groundwork for understanding its importance. In an AI model, tokens are the basic data unit. They are created using training samples of words, images, videos, and audio.
Tokenization is the procedure that divides each piece of data into smaller components. To execute inference and produce a precise, pertinent result, the model learns the relationships between tokens during training.
The term "throughput" refers to the amount of data that the model can generate in a specific amount of time, typically denoted in tokens. This quantity is determined by the infrastructure that runs the model. Higher throughput leads to a higher return on infrastructure. Throughput is commonly expressed in tokens per second.
The duration between entering a prompt and the beginning of the model's response is known as latency. Faster replies result from lower latency. There are two primary methods for calculating latency:
- Time to First Token: An estimate of how long it will take the model to execute a user request and generate its first output token.
- Time per Output Token: The time it takes to generate a completion token for every user querying the model simultaneously, or the average interval between consecutive tokens. The additional terms for it include token-to-token and "inter-token latency."
Although they are useful benchmarks, time to first token and time per output token are only two aspects of a broader context. Even yet, concentrating just on them can result in a decline in cost or performance.
The effectiveness with which an AI system transforms electricity into computing output is measured by its energy efficiency, which is quantified as performance per watt. Organizations can reduce energy consumption and maximize tokens per watt by utilizing accelerated computer platforms.
The Resurgence of On-Premises & Hybrid Infrastructure
Many businesses are rediscovering the benefits of on-premises and hybrid architectures as AI enters production. This acknowledges that diverse workloads necessitate different operating frameworks, not a rejection of the cloud.
Three benefits of hybrid and on-premises techniques are crucial for production AI:
- Businesses demand more control over the locations of data, models, and inference pipelines, particularly where regulated data and proprietary information are involved.
- Stable and predictable cost structures are advantageous for sustained inference of workloads. Cloud elasticity and the financial stability of on-premises infrastructure are balanced in hybrid setups.
- Requirements for data residency, compliance, and governance are getting more stringent rather than easier. By using hybrid architectures, businesses may satisfy these demands without impeding innovation.
These factors change from "preferences" to "requirements" as AI demand shifts from rapid experimentation to steady state manufacturing.
The Hidden Cost of AI Inference & How to Manage It Effectively
The fundamental issue is that inference is not free. With large language models (LLMs), the computational resources needed for each prediction might be substantial. We can think of the entire inference process as a compute-driven activity that generates predictions.
Consider your AI model as a high-performance sports car. Purchasing the car is training. Inference is the price of petrol, tires, and maintenance every time you drive it. You spend more money the more you drive (more inference requests). Scaling AI inference requires exponential resources, in contrast to a conventional software program.
So, how can businesses bring inference costs under control without slowing down innovation?
- Quantize Your Models: Decrease the model's parameter accuracy. This is similar to reducing engine size to increase fuel economy without significantly reducing speed.
- Optimize for Specific Hardware: To accelerate computation, use specialized devices like TPUs or GPUs.
- Implement Caching: To prevent recalculation, store frequently requested forecasts.
- Explore Model Compression Techniques: Minimize the model's size without appreciably affecting its accuracy.
- Monitor Costs Aggressively: Monitor inference expenditures and identify areas for improvement.
It can be difficult to put these optimizations into practice. Accuracy, delay, and cost must all be carefully balanced. Optimization efforts can be misdirected in the absence of appropriate profiling, wasting time and money. Imagine dedicating weeks to the optimization of a function that contributes only 5% of the inference time. Start by concentrating on your model's most computationally expensive components.
Making inference affordable is critical to the development of artificial intelligence. The necessity for optimization increases as models get larger and more intricate. Businesses that put an emphasis on effective inference will have a big competitive edge and be able to fully utilize AI without going over budget.
Top 2 Effective Optimization Strategies for Inference Economics
The main goal of efficient inference economics optimization techniques is to lower operating costs while maintaining excellent performance and accuracy. Organizations employ techniques like workload optimization, intelligent routing, and model compression to attain efficient resource utilization.
By carefully controlling latency, throughput, and model size, businesses may deliver prompt responses without incurring unnecessary infrastructure costs. Ultimately, these strategies enable AI implementations that are cost-effective, scalable, and performance-driven.
1. Optimizing Token Budgeting Strategies
In the Inference Economy, where tokens are the primary billing unit in the majority of AI application programming interfaces (APIs), token budgeting solutions have become crucial for businesses managing the rising costs of AI model inference. Inference charges are determined by counting the number of input and output tokens that large language models (LLMs) handle.
As the use of AI has increased worldwide since 2023, businesses may have to pay tens of millions of dollars each month for high-volume applications like chatbots or data analysis tools. This has led to the creation of automated ways to limit spending. To optimize resource allocation without interfering with operations, these solutions use intelligent agents that prioritize lower-cost queries, control access to expensive models when budget limitations are approaching, and monitor utilization in real-time.
Token budgeting is frequently implemented by deploying cost-control agents that are linked with corporate systems. These agents set predetermined thresholds to prevent overspending, such as immediately blocking access to heavy models like GPT-4 when 80% of the budget is achieved.
To maintain service levels while adhering to budgetary restrictions, these agents can dynamically divert enquiries to lighter, less expensive options or queue non-urgent jobs. Administrators may instantly modify budgets based on usage trends and predictive analytics because of integration with enterprise dashboards, which offers real-time visibility on token consumption. By using machine learning to predict token requests, these systems allow for proactive modifications that are in line with corporate aims. In these configurations, dynamic routing is an additional tool that improves task-level efficiency.
The effectiveness of these strategies is already evident in real-world implementations. Many large enterprises have seen meaningful cost savings by optimizing how inference is managed. For example, some financial institutions have reduced AI-related expenses by nearly 35% using predictive models to better control usage. Similarly, an e-commerce company implemented intelligent model routing to direct queries to more cost-efficient models without affecting performance, cutting overall token spend by around 40%. These results highlight how thoughtful token budgeting and optimization can scale across organizations, giving businesses tighter control over inference costs while directly improving profitability in the inference economy.
The budget allocation equation, which ensures that overall spending stays within limits, is a crucial mathematical basis for these methods:
\text{Budget} = \sum_{i=1}^{n} (\text{Tokens}_i \times \text{Cost_per_token}_i) \leq \text{Total_Monthly_Limit}
To ensure fair distribution and prevent budget overruns, this equation applies constraints at granular levels, such as per-user or per-department limits. It allocates expenses across various use cases, including development versus production settings. Businesses can model situations and establish thresholds for optimal efficiency by using optimization algorithms to solve this iteratively.
2. Model Distillation Methods
Model distillation, also known as knowledge distillation, is a smart machine learning approach used to build smaller, faster, and efficient AI models. A large “teacher” model transfers its knowledge to a lightweight “student” model. Instead of relying only on hard labels, the student learns from the teacher’s probability outputs, capturing deeper patterns.
Important components that promote efficacy include:
- Temperature Scaling: Softens probabilities to reveal hidden class relationships
- Soft Label Training: Enables richer and more meaningful learning
- Balanced Loss Function: Combines teacher guidance with true labels
The core distillation objective is:
L = α · KL(σ(zₜ / T) || σ(zₛ / T)) + (1 − α) · CE(y, σ(zₛ))
Advanced methods further enhance results:
- Online Distillation: Models learn together without a fixed teacher
- Feature-Based Distillation: Transfers internal representations
- Attention-Based Distillation: Preserves focus patterns in transformers
The outcome is highly efficient models that cut inference costs by up to 10x while maintaining over 95% performance. This makes AI deployment practical on mobile devices, reducing latency, saving energy, and enabling scalable real-world applications.
4 Key Decisions Every CEO Should Consider Before Investing in AI Infrastructure
Businesses that truly benefit from AI typically take a careful approach to infrastructure decisions. When assessing AI infrastructure, executives or decision makers should take four important factors into account.
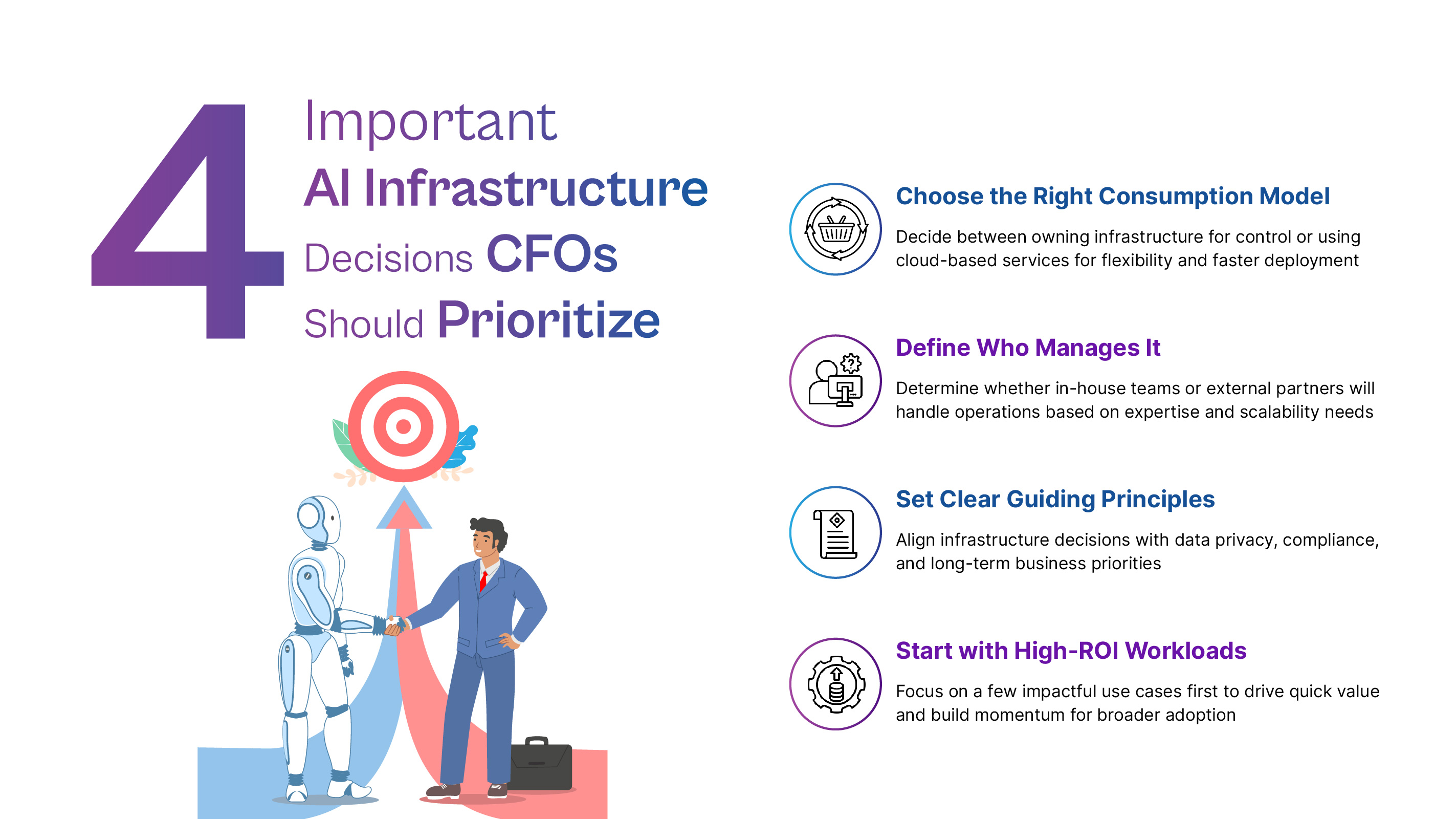
1. Select a Consumption Model
Businesses must choose between using computers as a service or maintaining their own infrastructure. Infrastructure ownership via capital investment offers long-term control and efficiency. Flexibility and faster deployment are provided by using computers as an operational expense.
Neither model is always accurate. Workload growth, financial strategy, and operational capabilities all play a role in making the best choice.
2. Defining Infrastructure Management Responsibilities
AI infrastructure necessitates specific operational knowledge. It is up to organizations to determine whether management duties will change over time, whether a partner will operate the environment, or whether internal teams will manage it.
In the end, a slightly enormous infrastructure will be less expensive than an infrastructure that no one is competent to manage.
3. Establishing Clear Guiding Principles
Organizational interests, not just economic considerations, influence some infrastructure decisions. Requirements for data sovereignty, regulatory considerations, and guidelines regarding the processing of sensitive data are a few examples.
Before making significant investment decisions, an infrastructure strategy should be designed according to these concepts.
4. Focus on High-ROI Workloads from the Start
Building infrastructure before determining the use cases that would provide value is a frequent error. Two or three targeted workloads that produce tangible improvements are usually the starting point for successful executions.
AI copilots for analysts or support teams, operational optimization tools for supply chain management or logistics, and internal knowledge assistants driven by search-augmented generation are a few examples. Organizations can achieve rapid results and create momentum for wider adoption by beginning with targeted applications.
Practical Strategies for Optimizing Inference Costs
Businesses are aggressively seeking improvements in several technical fields to successfully reduce the costs associated with AI inference. In this context, cost optimization usually results from either more effective use of computational resources or faster inferencing/lower latency.
The following are some of the main developments that are reducing costs:
1. Hardware Optimization
GPU Development: Examples like NVIDIA's Tensor Cores (such as the A100 and H100) and Google's TPUs (Tensor Processing Units) concentrate on improving the types of computations that are most frequently used in deep learning models. This speed is made possible by architectural advancements that enable more parallel data processing, which is essential for managing the massive datasets commonly utilized in artificial intelligence. GPU manufacturers are always pushing the envelope to create computers that are more efficient.
2. Software Optimization
Model Quantization: By reducing the resolution of the numbers used in computations (from floating-point precision to lower-bit integers), this strategy minimizes the size of the model and accelerates inference without significantly compromising accuracy. Quantifying data reduces the amount of computational resources required by making models faster and lighter.
3. Middleware Enhancements
Model-Serving Frameworks: Tools like NVIDIA's Triton Inference Server optimize the deployment of AI models by enabling multi-model serving, dynamic batching, and GPU sharing. These features boost GPU throughput and resource efficiency, which lowers operating costs.
4. API Management
Auto-Scaling: Features that automatically scale the number of active server instances in response to demand are a feature of contemporary API management solutions. This implies that fewer resources are used during times of low demand, which reduces expenses. On the other hand, the system can scale up to provide steady performance during periods of high demand without permanently allocating resources.
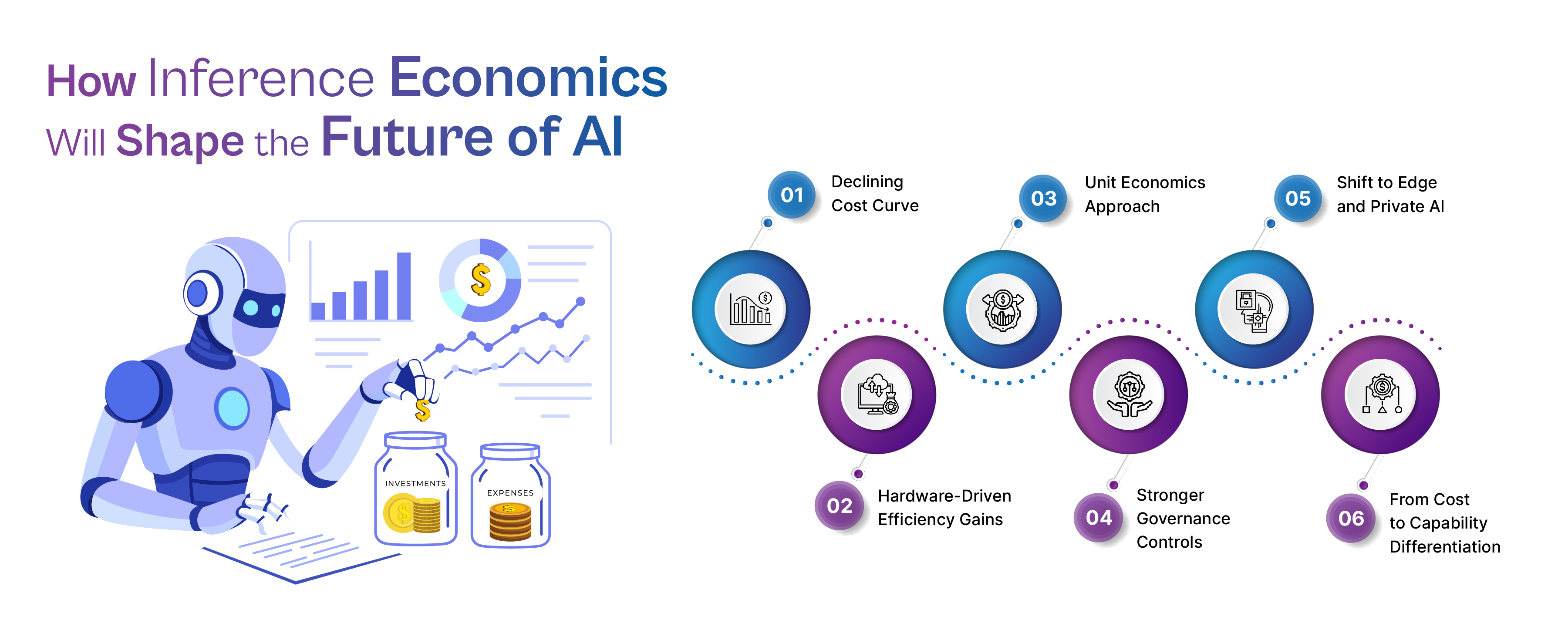
How Inference Economics Will Shape the Future of AI
Inference economics is redefining how organizations approach AI investments. Unlike traditional IT costs, AI inference spend is highly variable, usage-driven, and often difficult to forecast, making financial control a real challenge. As costs fluctuate and scale with demand, businesses must move beyond assumptions and adopt structured strategies to manage, optimize, and justify AI spending effectively.
- Declining Cost Curve: Baseline AI capabilities are becoming 40–900x cheaper over time, while frontier models remain expensive due to their advanced performance and limited commoditization.
- Hardware-Driven Efficiency Gains: Continuous improvements in GPUs and infrastructure significantly enhance price-performance, allowing organizations to process more workloads at lower costs.
- Unit Economics Approach: Businesses must track cost per workflow, department, or outcome to gain clear visibility and enable accurate chargeback models across teams.
- Stronger Governance Controls: Budget limits, guardrails, kill-switch policies, and anomaly detection systems are essential to prevent unexpected cost spikes and ensure financial discipline.
- Shift to Edge and Private AI: Workload placement decisions should be based on utilization, latency requirements, and data privacy needs, not just cost-saving assumptions.
- From Cost to Capability Differentiation: As inference becomes more commoditized, competitive advantage will shift toward delivering better performance, accuracy, and user experience rather than just minimizing costs.
Conclusion
AI is not an exception to the rule that every significant technological change includes a period of uncertain economic conditions. Today, we are in that window. Massive infrastructure is being developed at previously unheard-of speeds, often at prices below cost, as foundation model providers compete hard for market domination. Not all of them will survive this phase, but the infrastructure they are creating will endure and propel the next wave of innovation.
For businesses, this is a unique opportunity. It has never been easier or more affordable to get access to such advanced AI capabilities. Businesses may test, grow, and build AI-driven workflows without fully investing in infrastructure. There is a cost to this advantage, though: the current pricing dynamics are not expected to persist indefinitely.
Costs may increase, prices will stabilize, and competition will become more limited as the industry develops. Because of this, businesses must take strategic action right away. Long-term robustness will be ensured by establishing solid foundations in inference economics through transparent cost visibility, governance, and optimization.
Those who discover how to effectively handle AI will be the true winners, not simply those who adopt it early. Because controlling how strong models are deployed, scaled, and maintained over time is ultimately more important for success in the inference economy than simply having access to them.
Transform your AI investments into measurable business outcomes, partner with Cogent Infotech to build cost-efficient, scalable, and future-ready AI infrastructure.
FAQs
1. What is the AI inference economy?
The market for using trained AI models in production, where value is produced through ongoing, high-volume inference, is termed as the AI inference economy.
2. Why are AI inference costs becoming a major bottleneck?
As AI applications expand, centralized cloud pricing becomes unsustainable due to inference workloads that are constantly on, latency-sensitive, and scale with consumption. For AI inference infrastructure, Cogent Infotech provides an affordable substitute.
3. How can I reduce inference costs?
Focus on four layers: facilities (right-sizing, autoscaling on queue or batch metrics), platform (cost observability and FinOps so you can attribute spend and take action), runtime (batching, production-grade inference servers), and model (quantization, smaller or distilled models where appropriate).
4. What is quantization and how much does it save?
Quantization reduces model size and memory consumption by reducing the numerical accuracy of model weights (e.g., from 32-bit to 8-bit or 4-bit). Depending on the model and workload, reported savings often range from 60 to 70%; real outcomes differ.
Real-World Journeys



